Long story short, there was a DDoS and bot attack that my company experienced some time ago on specific API services. This incident made me question why these attacks always seem to happen at the exact moment, despite having implemented an alerting system. I wondered why we couldn’t predict an attack in advance, such as a few seconds before it actually occurred.
After conducting a “somewhat” research with my coworkers, I discovered that we can perform anomaly detection based on API response using two different approaches: real-time detection or pre-trained detection.
Anomaly Classification May Differs from Others
Basically, Isolation Forest algorithm operates by isolating anomalies from normal data points. It achieves this by computing anomaly scores through a successful binary search tree (BST) process. The algorithm compares objects based on their variant score anomalies and determines which object deviates the most from others.
The variant score anomalies are measured in terms of the object’s threshold or path length. A path length value between 0 and 1 indicates the degree of dissimilarity from normal data points. If the path length is close to or greater than 1, there’s a high probability of an anomaly. Conversely, if the path length is less than 0 or close to 0, it suggests the absence of an anomaly1
To detect anomalies in an API response, it’s crucial to establish a clear understanding of the features classification that defines an anomaly. However, during my exploration, I encountered the challenge of not having a definitive definition for classifying anomalies2. This classification can vary depending on domain knowledge and specific circumstances (it might also be different with other companies or institutions). However, I’ll provide an example of what may cause an anomaly based on the acceptance criteria used in my current workplace
- status code: if the HTTP response status code provided isn’t returned as 200, then the request is considered an anomaly
- response time: if the HTTP response time during the request process is more than 3 seconds (for overall request, we have already measured). then this will be considered as an anomaly
But of course, this is actually a very minimal classification, and there are a number of things that we should also consider (for example: HTTP method, response body, user-agent, IP address, cookie). But putting all of those aside, we’ve got a standardization for describing an anomaly
Extending Isolation Forest for streamlining the HTTP request
Practically speaking, we began to create an internal library to detect this so, we can just do right away import that without having explained them one by one :D
from src.ml import ApiAnomalyDetector
anomaly_detector = ApiAnomalyDetector(
url="https://jsonplaceholder.typicode.com/posts/",
anomaly_request_url="https://jsonplaceholder.typicode.com/posts/-1",
threshold=0,
)
anomaly_detector.collect_training_data(100)
# here, I just experimenting with what kind of results that
# I will get if I applied a feature selection process
anomaly_detector.detect_anomalies(is_selection=False)For this work, I try to use the JSONPlaceholder tools for testing purposes, and it will collect about 100 samples of the request
You might be wondering why I added a parameter called anomaly_request_url. This parameter itself aims to be a differentiator/anomaly when the HTTP request process is running. The first URL parameter is a valid path while the second parameter will give you two different conditions:
- first, it will get the status code 404
- second, the response time that will be received will be longer since it will be redirecting to the invalid path
and this is the result i got after i plotted it
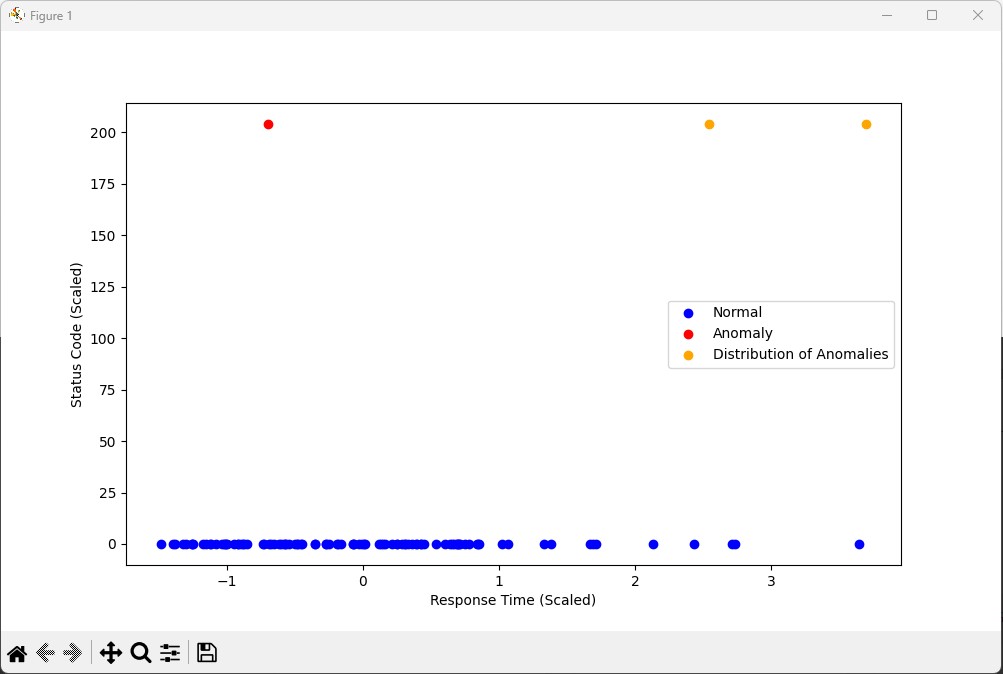
As you can see, based on that there’s an overview of the anomaly distribution based on the previous code setup. The red plot defines as a single anomaly (in which the status code is outside 200, but it looks like it might’ve been within 200 since i didn’t set up the plotting correctly HAHA). While the yellow plot indicates more than one anomaly variation.
As you can see based on the X label, the total response time also affects the occurrence of anomalies. Above this, the response time is more than 2 seconds, and there are 2 anomalies, while for the response time below that, there is little possibility of an anomaly. For further evaluation and in-depth performance analysis, I didn’t calculate the accuracy, recall score or false positives, or the like. So, rest assured, I can’t say for sure that this experiment was successful.
Interesting Takeaways
Now, the interesting part is here. If we go back again to my previous statement regarding real-time anomaly detection and pre-trained datasets, there will be a knowledge gap that I can use as material for further implementation. I just noticed, in general, this solution is made to quickly detect an anomaly and be able to predict before an attack occurs. But what needs to be underlined is :
- How can we ensure the training of datasets captured while the API services process is running non-stop? One solution I came across involves employing background processing for analyzing each request during periods of low API traffic latency. This approach allows us to perform analysis without compromising the functionality for real users and without introducing any discrepancies to the dataset model3
- If we don’t implement real-time processing, which involves collecting data first, training separately, and subsequently implementing the detection features, a gap will arise between these stages. As mentioned earlier, when dealing with high-traffic users, the trend detection itself will vary. If we stick to using reconstruction-based models for anomaly detection, it will encounter or might lead to changes at certain points. This is because the feature detection is performed with existing data models and then compared to data that is near the anomaly point, thus, whenever the data models deal with an abnormal dataset it will give the invalidity
Wrap-it up
All of this experimentation and research is very intriguing to me. Though, I’m aware there are some bottom lines that need to be considered like :
- I didn’t conduct an in-depth analysis after training the data model, because you know, I’m lazy to do it HAHAH. But, for some reason, there might be biases and inaccuracies in the experimental results. I discovered instances where certain API responses were incorrectly labeled as anomalies, even though they weren’t failures or anomalies themselves. This occurrence can be attributed to false positive labels. To solve this issue, various methods can be implemented, including evaluating the training process
- The request anomaly URL parameter in the code above is actually unnecessary. In real-world scenarios, anomalies typically arise from external parties attempting to attack our system. Therefore, this parameter is merely included as a dummy parameter and holds no practical significance.
Footnotes
-
Tony Liu, Fei; Zhou, Zhi-Hua (2008). “Isolation Forest”. IEEE Xplore: 413–422. doi:10.1109/ICDM.2008.17 ↩
-
Geethika, Deshani & Jayasinghe, Malith & Gunarathne, Yasas & Gamage, Thilina & Jayathilaka, Sudaraka & Ranathunga, Surangika & Perera, Srinath. (2019). Anomaly Detection in High-Performance API Gateways. 10.1109/HPCS48598.2019.9188100 ↩
-
Ifthikar, Arshardh & Thennakoon, Nipun & Malalgoda, Sanjeewa & Moraliyage, Harsha & Jayawickrama, Thamindu & Madushanka, Tiroshan & Hettiarachchi, Saman. (2021). A Novel Anomaly Detection Approach to Secure APIs from Cyberattacks ↩