Strong Consistency and Linearizability
Recently, there were several issues that I’ve encountered at my work regarding the data integrity mismatch which related to the user job application status. One of the primary roots cause it’s back then our SQS consumer services are getting timeout and crashing, so all the processing of a batch message of the user job application status happened partially and it was leading towards out-of-order state transitions. The other root cause that takes place is that our SQS consumer fails to write/save the user job application status to our database regardless of whether we’re already implementing a retry/fallback mechanism. In addition, there are some delayed events where our systems have an inability to process those messages.
Based on what I’ve read, SQS is designed for high-reliability and durability for processing all the data and it’s unlikely to “throwing away” during data interoperability. However, our distributed systems itself wasn’t perfect and it was leading to the disruptive issues that took place. So, after having discussions with the engineering team, I find that faults heavily rely on our distributed systems rather than external parties. This can be concluded to the actual root cause that was related to business logic violations and improper data configuration between two services which were used during these events1.
To give you a gist of the issue, perhaps this simple illustration might depict what are the issues that were happening
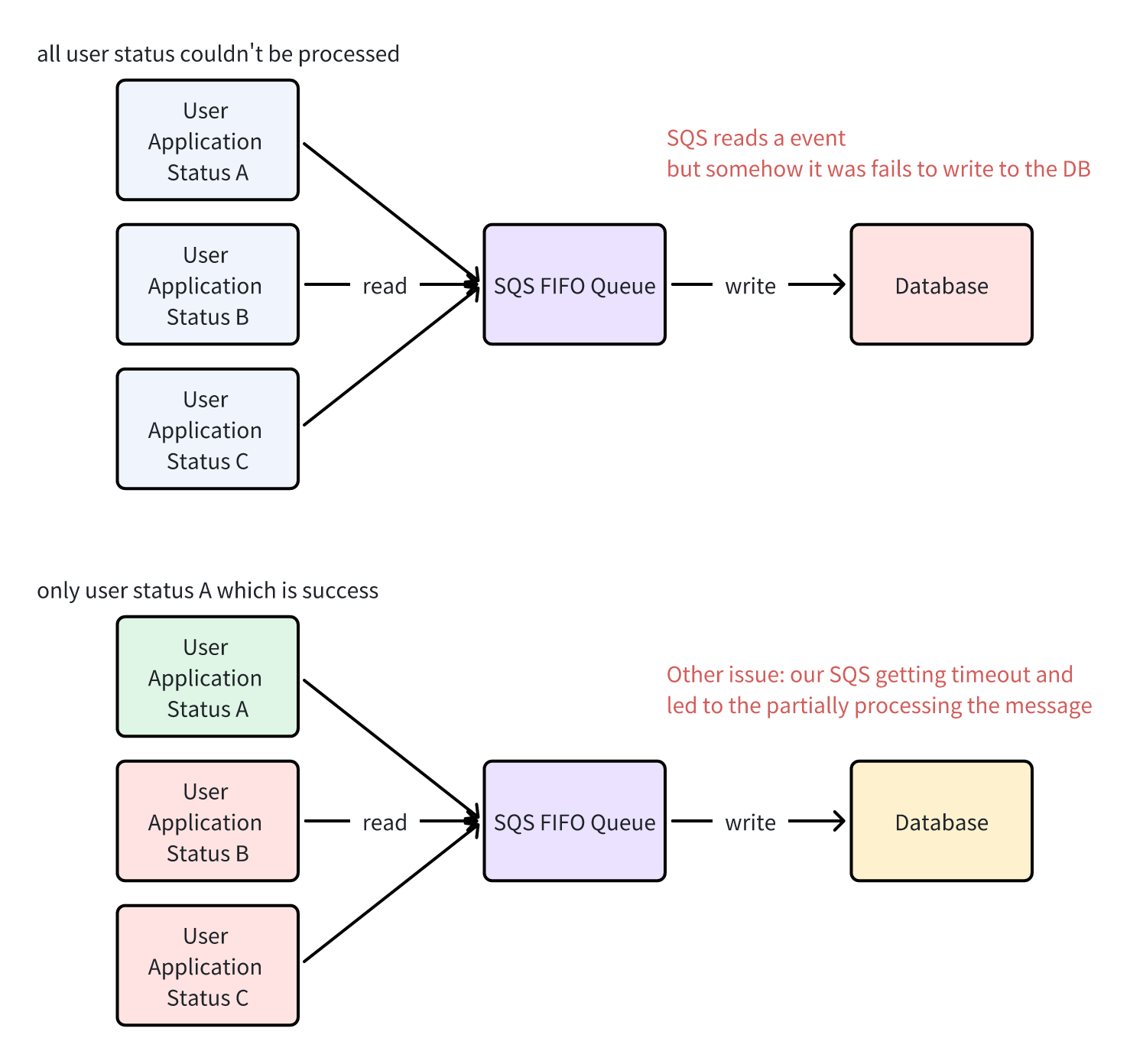
At first glance, I was thinking about applying linearizability concepts for testing purpose, when this issue resurfaces in our distributed systems. However, there’s nuance to that concept when it comes to SQS services which we primarily use when that issue takes place. Somewhat, when I tried to apply that concept, it seemed to be a bit complex due to the various reasons. After a few hours reading several articles and documentation, there are key points that I understand:
- The linearizability concept is about ensuring the operation when delivering or processing the shared data should be atomic and consistent with real-time manners. Batch operations in SQS itself aren’t designed to be atomic operations (meaning some messages are successfully delivered while others could fail).
- In addition to that, SQS, specifically using FIFO-based, is not lineariazabilty by default. Since the primary purpose of SQS is only guaranteed order per message not across distributed systems entirely and it still doesn’t determine the linearizability even using ordered queue messages.
- However, we can still apply linearizability principles with several considerations: it’s only for context testing, specifically testing for messages in order to verify correctness and also to control the state changes during message processing. By all means, we only validate the state transitions that are triggered by other interactions (example: the event being triggered by another message or automatically triggered within time constraint).
Basically, the testing that previously could have applied linearizability concept now is shifting towards testing for state transitions or we may call it strong consistency in the state machine operations within distributed systems. We still may apply the principles of linearizability, especially in distributed systems where multiple events update shared state, but with several considerations as stated previously.
In this specific context, the strong consistency that takes place is more towards real-time relationships between two services, and how the state reflects a consistent sequence of events. All the messages or data that were being delivered might not be preserved immediately after successfully read by our SQS, but the corresponding system will be updated and convergence over time based on specific needs and all the propagated data must be consistent.
Real-world failures
The primary issue was there is a data mismatch which is related to the user job application status. This issue swarming to both our event-driven systems, which were highly dependent on each other. The first services were employer services, which will act as to serve all the services related to managing user application status and the other services were jobseeker services, which would be the primary services to users (re: jobseeker) during applying for any job and their job applicant would land on employer services. Let’s dig deeper into the actual issue that happened.
There were several requirements and indicators to get the user hired, or at least if it’s not their day, their job application status might get KIV, rejected or even just shortlisted. In addition to that, our business objectives have another requirement that the jobseeker could be “PING”-ed the employer to get the update or notify them to start sorting out their application. All of these situations and conditions eventually involve temporal correctness based on the date time which user job application status gets processed by employer or initial created time when the jobseeker started to “PING” the respective employer.
Let’s take a look at the illustrated diagram below based on one of the issues that I’ve encountered to depict based on the requirements
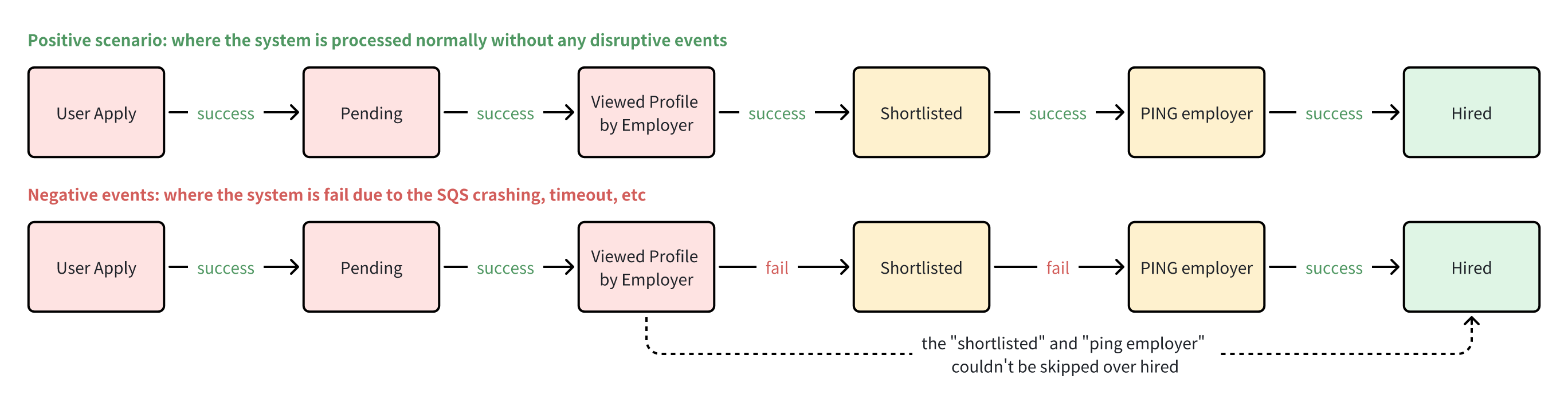
What we’ve looked at in the examples illustrative diagram above, the negative events represent the issue that I’ve encountered and without a doubt, is becoming a crucial issue since it will face real-world consequences both for employers and jobseekers. Not to mention that, these issues directly degrade the user experience, such as we face a complaint about incorrect notification being triggered, disrupt internal automation business workflow (broken automation when automatically “PING”-ed the employer when reached the limit), or inaccurate talent funnel to further data exploration and analytics.
As per now, the question arises to me: how might we prevent this issue in the future and what kind of testing methods could possibly do to detect these anomalies? The primary objectives of this testing is to take the test our distributed systems process events eventually reach a correct with valid state and also logically, in ordered manner. So, there’s no more out-of-order transitions that take place that leads towards inconsistency.
Testing around consistency
When I started to think the linearizability principles might take part in this testing context, I was still a little bit unclear about how we might carry out the testing process. At the moment, I don’t think about immediately implementing automated checker around this issue, since I need to have a solid ground/approach to conduct the testing process. For a moment, I started to build a test harness only around SQS services and just checking the correlating API responses once the messages were successfully downstream to our systems. However, it is still not adequate enough to cover the full event stream such as end-to-end testing, starting from SQS messages until the state of transitions has been written in our database and services. Since there’s still a potential issue that might arise, such as the messages fail to update to our database due to the race condition or some delayed events during consumer services crashed midway2.
Immediately, I try to extend the testing harness to covers from full event stream by checking the API responses and validating whether the respective response has been saved/updated in the database or not. However, there are questions that bug me off during implementation with this approach, and it was related to the: What kind of testing layer should I test of correctness? Is it or in API levels or logs-based? Deliberately, I tried to dig deeper and found several takeaways (pros and cons) about how I might choose which layer that I want to test:
- When we’re going to test based on collective logs, it will give us a complete trace of what happened among services. We can reconstruct the chained event and it was great to trace back the actual root cause or incidents and become valid justification for why the issue took place.
- However, the main disadvantage is testing based on logs isn’t always in real-time, and it’s quite difficult to automate consistently for regression testing. On the other hand, if the logs are growing complex, there’s a possibility that it will lead to incomplete or delayed data (which is abruptly raise another issue)3.
- When we’re going to test based on API responses, the primary advantage is that it is faster and reliable, especially if it will be lot easier to automate. Another thing is, it also has extended capabilities to test which are using assertion, during integration, to simulate the real-world scenarios and much more represent what user/client experience wants.
- However, the primary cons when only testing for the API is that we only know whatever the final outcomes are based on the API response. Otherwise, we couldn’t always see why a transition state is being triggered.
The best outcome was to have hybrid approach by combining checking from API response, validating through database by queries to ensure the event has been triggered and updated in sequence and double-check with the logs for critical journey. Surely, there are many things that need to be implemented if I want to use this approach, but what I think now is one of the suitable options to implement. High-level architecture for this approach can be viewed in this illustration below
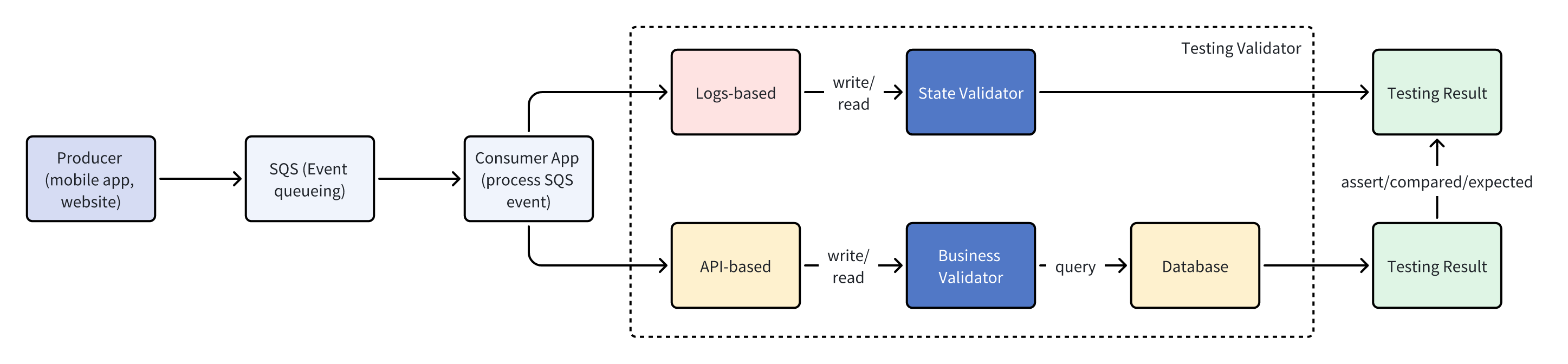
As you can see in the architecture diagram, once the messages are processed and delivered, our backend system will send them towards our services and will be consumed by the user-facing API, alongside all the messages related will be written in the database. In addition to that, the logs are automatically generated by the backend. Notice that there will be 2 different testing validators for each process. The testing validators itself are some sort of logic that were written using Python and serve to identifying whether all the events and state transitions are correctly actual with the user-facing API.
The state validator used to check the logs generated from the system and will conduct validation to find state inconsistencies, data that may be lost or partially missing during interoperability. While the business validator is just like ensuring the message content which was obtained from the API response has sent actual data and is presented with actual business logic. To avoid potential data mismatches in the database, a query must be performed to check the final testing state, whether the data received from the API response matches what is in the database or not. This needs to be confirmed by checking business logic correspondence, such as looking at the timestamp or incremental counter on each request ID.
Once we get the result, we will make an assertion between testing result for logs-based and API-based. In other words, once both validators have completed the respective checks, testing harness will perform cross verification to ensure the result which comes from API-based and logs-based are aligned with each other and sequentially stored in the database without any discrepancies. By comparing these4, we may identify subtle consistency bugs that occur within our distributed systems. For instance, cases where the saved logs show an indicated change of state from user status, but the database was never updated or any response from API returned incorrectly.
Footnotes
-
As per mentiond in the CAP theorem, you can’t simultanteously have: strong consistency, high availability, and partition tolerance. The case that we’re facing is causing disruption in our distributed systems that happened during migration, hence the downtime occurred. SQS natural mode is eventual consistency which means it’s enforcing stronger guarantees while require careful synchronization, transactional semantics and idempotency to ensure the data integrity. ↩
-
These scenarios precisely where eventual consistency might show up, since the system will converge to the correct state but not immediately in real-time manners. In practical testing I carry out, I may not include logic such as delayed events or retry to make the testing process more realistic, any inconsistency or mismatch is subtle and considered as a real bug, not just propagation of the data ↩
-
Somehow, we’re also facing the issue when our logs are growing complex. This issue might be identical to what it called it as state space explosion. Our symptomps indicated that when the concurrent logs are growing, it’s causing possible orders and much harder to “deterministically” reconstruct the chained event. Leading to the partial or incomplete logs ↩
-
We emphasize the multi-layer validations as a observational linearizability, to essentially reconstruct the chained event within relationships between our services and checking the observable state whether it’s consistent and matches the linearization. If it’s consistent (based on the logs, API response and database), our system behaves as expected and it’s linearizable. However, if the state is inconsistent, it will identify as linearizable violation. ↩