Notes: This is a personal reflection based on my own journey. Experiences may differ, and the narrative might feel long or jumpy at times, that’s simply how the learning unfolded for me
Early years
Before joining my current company, when I was still working as a Backend Engineer, I noticed how testing strategies evolve drastically depending on context, scale, and priorities. Back at the software house, our testing approach focused heavily on validating core functionality and ensuring critical flows worked as quickly as possible, usually because we were always racing toward client presentation deadlines. Once things looked stable enough, we’d move into UAT and wait for sign-off before release.
Most of our testing was manual or exploratory, what I’d call “scrappy testing” combined with basic smoke tests before and after release. CI/CD pipelines existed, but automation only covered critical or repetitive flows. The staging environment was rarely touched unless we were already in UAT. It wasn’t anything fancy, basically a production mirror without scheduled backup routines. Performance testing only happened when stakeholders started asking, “Kenapa sistemnya lambat banget dah?” and load testing was almost performative until someone complained 😂
Why does scrappy testing even work?
Well, if I had to guess, it probably came down to two things (though not limited to them):
- User behaviour was predictable and limited. We only had a handful of user interactions, and usage patterns weren’t diverse. Fewer variations meant fewer edge cases. We didn’t even need session replay, and users’ feedback was straightforward and usually already anticipated.
- Bugs were mostly deterministic. With small, controlled interaction and a system designed for known peak loads, issues are rarely escalated into data corruption or critical issues. Bugs were treated as binary: valid or not, data or functional. Very straightforward.
Looking back, most bugs our QA engineers reported were easy to reproduce and fix. We didn’t bother with risk-based prioritisation. Everything got fixed, for example, trivial UI copywriting typos, we immediately fix. None of the issues were too complex, we could replicate production bugs locally without much effort. That’s largely because we weren’t dealing with scale, distributed complexity, or large user populations. Most projects were internal dashboards for Zurich Indonesia, CIMB Niaga, and government institutions. Maybe I handled ~5000 users in total, mostly internal.
Technology and tooling weren’t complicated either. No AI or LLMs back then. QA tracked bugs in Jira or even Google Docs, managed test cases in Google Sheets, and built UI automation with Selenium. API automation was done in Postman scripts, integrated with GitLab CI/CD using Newman, and results were pushed to Slack, which already felt “advanced” to me at the time. Tasks are usually distributed from the PM → QA Lead → QA members. These were the earliest memories of how QA operated when I first entered the professional world.
Moving to ~100K daily active users
When I joined my current company as a new SDET (Software Development Engineer in Test) in the mobile team around 5 years ago, the scale was different. Our apps served at least around 80–120K daily active users with more than 50 million user sessions each month. We had long-running UI automation built with Selenium and Appium, utilising a few devices that were integrated into a customised device farm, as we didn’t have the budget to pay for AWS (sad…), a dedicated testing infrastructure for mobile, and API automation using a customised Postman script, which is integrated with Jenkins, similar to what I experienced in my earlier days. The difference was that the software testing lifecycles here felt more structured, although automation schedules, priorization and result visibility were still quite scattered. Even so, the testing lifecycle was much more defined. From running automation to manual exploratory testing, logging issues, and creating tickets, everything followed clear guidelines: mature, established, and properly documented.
It was during this period that I realised the “old ways” of testing were starting to hit their limits. They worked well in a smaller context, but they couldn’t scale well at the certains level anymore. Some parts of the old process still held up, but others needed to evolve. UAT was still implemented, especially when collaborating with Google, Microsoft or other external vendors, but much less often compared to my early years. Meanwhile, unit tests, integration tests, and contract tests became “de facto and must have” across the engineering department, including the mobile team itself. We also adopted gradual rollouts to reduce crash risks and feature flags for experiments, like social media login or dynamic homepage banners. At this point, I started to feel the shift in how we thought about testing and quality as a whole.
When the previous testing is no longer enough
If I have to remember correctly, mid-2022 until early 2023 was the major turning point that we needed to restructure the testing lifecycle, at least in the mobile apps team first. We have a big feature which has become a major trendsetter (talk about confidence, LoL) among jobseeker portal platforms in Malaysia, Vietnam and the Singapore region called “Drop Resume”. Practically speaking,the user just literally drops their resume, and our systems will parse the user’s resume and forward it into our internal talent pool so it can be searched by respective hiring managers. But eventually, we were struck by several incidents that we have a lot of issues related to the data integrity, availability, system performance, and also security issues. Well, I guess the biggest lesson learned back then, even though we already established and well planned before launching a new feature, we still couldn’t fully manage to prevent the risks since exhaustive testing is not possible.
Around the same period, the mobile team underwent on a major tech migration, rewriting the entire app from Kotlin/Swift to Flutter. You can imagine the workload, uncertainty, and quality challenges that came with a change that massive. At the same time, I began questioning how we defined KPI/OKRs for the QA engineering team, which is one of the main drivers for us to achieve primary goals and help the company to strive for the better. They felt too formal and heavily reliant on previous data (but not diving deeper to understand much more), rather than reflecting real impact or growth potential. It created the sense that QA was positioned as mere cleaners and gatekeepers, instead of contributors and enablers of engineering excellence. One of thing that I learned during that period was that the migration to Flutter, alongside the launching of the “Drop Resume” feature, made me realise I was measuring success by automation output, not impact.
That forced me to rethink again and ask: what does quality actually mean at scale?
This pushed us together with the Head of Engineering and QA Lead at the time, to rethink our direction. We knew we needed to elevate the role of QA, strengthen visibility, and build credibility through measurable and justified outcomes. However, we also had to face an uncomfortable truth: we didn’t yet have a solid software testing lifecycle. We adopted something close to shift-left testing, or agile-based testing, but it still leaned traditional and didn’t fully leverage the competencies or experience we already had. Our approach back then could be visualised roughly like this in terms of directing and making an alignment of QA’s OKR/KPI with the company objectives:
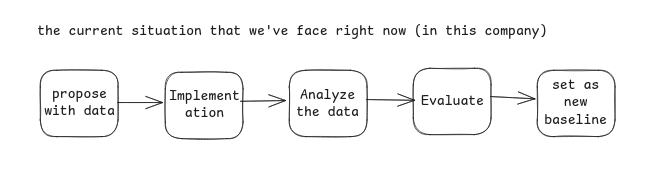
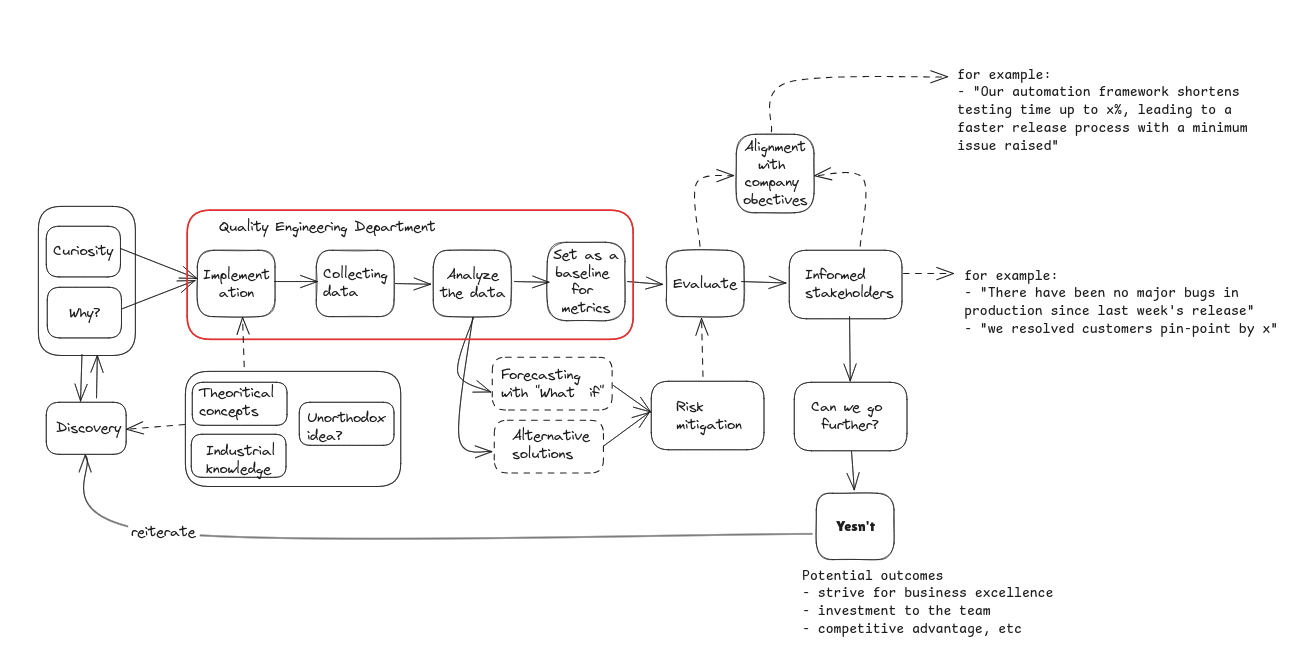
What it looks like now is very different. This is still a our concept and “corat coret”, an evolving sketch we started developing 2-3 years ago when we decided to reshape our STLC to better align with the company’s needs and targets, without losing the culture and values each of us brings to the team When we first began adopting this approach in Q4 2023 and throughout 2024, we ran into several challenges. The biggest concern was clear impact. Our work didn’t “translate” directly into revenue, which is expected, since we’re part of the engineering team. But it still raised questions about how our contributions should be measured. We had to find “indirect” ways to demonstrate value and influence outcomes that mattered to the business.
I’m not sure whether this concern is universal across companies or something unique to ours, but it forced us to think more deeply about how QA impact is defined, communicated, and justified beyond traditional metrics or industry practice out there
Along the way, I’d take a chance to be mentored through ADPList and met with Mas Genta and Pak Jason, whom I know through the ISQA telegram community. Although I’ve only had a mentoring session with Mas Genta twice and most of the time chat with Pak Jason (and once we’ve discussed in Google Meet), I’m incredibly thankful and grateful to them, that they were basically laying out the “Software Testing Foundation & Principles” to me, which is i can say that all the testing perspective must thinking holistically in every way of perspective that has to be. Is not just about automation, managing the quality expectation, finding and preventing bugs and such. Basically, they taught me a few shared principles that deeply remember: the difference between good and great quality engineers comes from why and when things shouldn’t apply.
+5M monthly active users and beyond
After being promoted to a senior position in early 2025, the level of complexity and the headaches that came with it grew rapidly. Some days it felt like my brain was stretched to its limit and might be blown away. In this phase, I realised that our previous approach to testing, such as hybrid automation + manual exploratory testing, or even the traditional testing pyramid, no longer fit the reality we were dealing with. Testing wasn’t just a responsibility of dedicated teams: it had become a distributed, cross-company problem. If I had to sum it up, we were facing at least four major pain points:
- Data (inconsistency, integrity, availability). Correctness is no longer deterministic, but it is also much broader, rather than just quantifying as a statistical measurement.
- Security. Attacks are continously happen, not just periodic events or one-time events, and then it goes away.
- Performance. Averages, reports, insight, or all of them don’t matter when we don’t take an actual action and turn them into practical improvements.
- User Experience. Small friction might feel harmless in isolation, but multiplied across thousands of users daily, it causes frustration and damages the company’s identity.
After moving to the core product team, security threats became a regular occurrence on a daily basis, you name it: bot attacks, DDoS, and other malicious behaviours. We conducted security and penetration tests, but much of the heavy lifting still relied on 3rd party vendors instead of internal teams. I wasn’t directly involved in those processes, but every quarter our Head of Engineering would brief us on recent incidents, recommendations for hardening, and whether any user impact occurred. We also set up monitoring tools to detect suspicious behaviour, including Cloudflare and several built-in AWS services, along with data protection mechanisms using Zero Trust.
Speed is undeniably important, but quality can’t simply be pushed aside in the name of speed. Whenever we talked about this by trying to find a balance between that, personally, it seems unrealistic to achieve since I started to believe that some things get harder to feat one by one, when our company/business/complexity starts to scale and grow even further. I’ve learned that choosing speed over quality (or vice versa) isn’t just a preference: it requires strong reasoning and awareness of trade-offs. This became a new part of my identity as a new person: decisions must be intentional, not habitual1.
Regardless of whatever “testing philosophy” or “engineering philosophy” I align myself with, the company’s goals still matter. Quality doesn’t become less relevant, but it must be contextual and practical. I need a mental framework to evaluate decisions: When should we prioritise speed? When do we hold the line for quality? What justification for a delayed release? Even something as simple as a sign-off before launching a new feature can turn into a tough Go/No-Go decision when deadlines are tight. It’s mentally exhausting at times because I have to delve deeper, some times taken up my sleeves willingly to have a better and contextual understanding of what my company views and what they would like to expect in terms of ‘speed’ and ‘quality’, but still protecting the quality where it truly matters.
Then, how about User Experience?
From the user experience side, we began shifting our approach by adopting Nielsen Norman Group’s heuristic evaluation for exploratory testing. QA started working closely with the UI/UX team to define guidelines so we could evaluate UX issues more systematically. As mentioned earlier, small friction can have a snowball effect into significant user dissatisfaction at scale, so we treated UX as a first priority of testing concern. By Q3 2025, stakeholders even introduced personal key results tied to UX findings: any QA members who identify heuristic-based UX issues earn measurable credit toward performance.
But how did we do that?
Well, basically, it’s been a long journey, and we went through several rounds of experimentation. One thing we learned early is that QA and UI/UX interpret usability differently, which means alignment is necessary if we want consistency. We need to ensure both teams are on the same page. A simple example I might say, “Oh, ternyata ada user yang bingung karena lihat pesan error yang susah dipahami” from a QA perspective, that’s a usability issue. But the real question becomes: what kind of issue? Why does it happen? What principle does it violate? That’s where we began adopting Nielsen Norman’s usability heuristics. Now, whenever we find UX issues, we categorise them clearly, understand the reasoning behind them, and avoid judgment based solely on QA viewpoints. Instead, issues are viewed more holistically, tied to how the system communicates with users, not just how we test it.
We also integrated AI tools to help QA evaluate and draft ticket details automatically, speeding up the workflow and reducing friction between QA’s daily tasks. But the main purpose is not only because AI has become the dominant trend, but I’d to think we as a company have undergone a digital transformation that pushes us to adapt. At my current company, we’ve reached a point where quality can be temporarily sacrificed for speed as long as we have the capability to recover quickly. And that recovery is possible largely due to AI, not through buzzwords like “self-healing automation or AI jargon”, but through how every member uses AI to work smarter, intuitively, automate repetitive work, and accelerate decision-making. Today, our QA role has evolved into what we call a Fullstack QA Engineer. Automation, performance testing, data testing and exploratory testing are the baseline: it’s considered as minimum expectations from the company. Additionally, we continually adopt new skills as we progress, particularly with the assistance of AI, which now supports our workflows.
Take for example:
- The QA team become more capable at handling user-facing incidents end-to-end. From responding to the report → investigating → prioritising → drafting a ready-for-work ticket → retesting after the fix → releasing → and communicating back to relevant stakeholders. The cycle is clearer and faster.
- Proactively build proofs-of-concept to test new tools or frameworks. I’ve seen my QA coworkers develop internal tools using AI, review test cases with AI assistance, analyse logs or API responses at such speed and even automate routine tasks that previously took hours.
These two examples are not limited to these. I’ve witnessed significant growth and progress across the team, not just in tooling, but in perspective and the willingness to experiment and improve.
Real challenge starts here
Working with medium-to-large-scale distributed systems has been a genuinely eye-opening experience for me: surprising, overwhelming, and sometimes shocking in ways I never expected. Even though I’m in the same company, the workload feels like a completely different world, not to mention now that I’m assigned to the core product team. The tools and processes might look familiar, but the scale changed everything.
On a daily basis, my responsibilities can be summarised as (though definitely not limited to):
- Be responsible for the overall quality of the core platforms, especially around data interoperability. We handle more than a billion internal API requests per month, process millions of resume data points weekly, track 400M+ desktop events, and manage over 200K daily token requests for generative LLM workloads in our feature and so on.
- Overseeing release quality for backend and mobile apps. I often jump into system-infra issues when other teams need help. Our ecosystem now consists of 150+ internal distributed services and dozens of data pipelines. Backend testing is mature, with 5000+ unit tests and ~80% API automation coverage (plus a good amount of flaky tests and “unexpected failures” 😂). The mobile team is transitioning to widget tests, though coverage still needs improvement. The biggest bottleneck, I think still related to the data testing: we still heavily rely on the integration and performance test, but do not touch the schema.
- Researching and developing something “productive” to have a major impact. This includes internal tooling, evaluating new tools, whether we are adopting or rejecting frameworks, experimenting with AI-driven workflows, and improving engineering productivity with careful consideration of cost, risk, and outcomes.
With lots of services, data, high level of cohesion between and a lot of things running around this and that, the responsibility is slowly changing, not just reducing bugs that appear in production, but how to do it when there is a bug, we have the main “foundation” for how to find out about the issue early or quickly, immediately recover and fix the bug, learned from the lesson. Well, it’s similar to the MTTR metric, only at the company I work in, the rules are currently adopted, it’s adjusted according to our culture and conditions.
Does it mean it’s shifted the perspective?
Yes…
As I mentioned earlier, traditional and even hybrid testing approaches no longer fit us. Over time, my perspective shifted (again). Instead of speed over quality, it has evolved into speed enables quality. Or more accurately, “Great software teams produce quality, and speed becomes its own consequence” In other words, speed isn’t the main objective by itself. It’s a deliberate outcome, something you get when the testing ecosystem is appropriate in the right context. When we understand our quality friction points, know which testing areas need restructuring, and recognise where the greatest potential improvements come from, speed naturally follows (am I wrong or wrong, which one is it, I don’t know). Quality becomes sustainable, not accidental and of course, it’s a long process, and I’d believe every organisation out there has a different perspective and culture regarding this situation. Well, there was no silver bullet to solve any complicated things.
Somewhat, the testing pyramid becomes inverted along the way with the journey that I had, and perhaps, what I pictured in my head when writing this was like this :
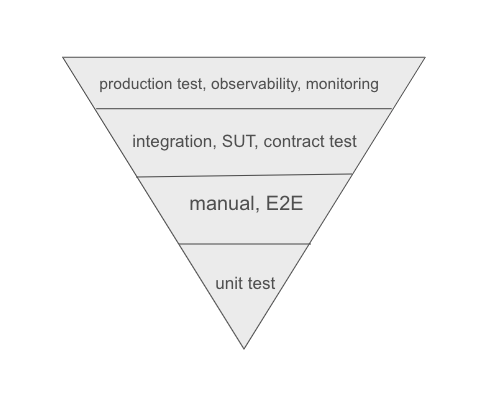
If the traditional testing pyramid is grouped or categorised by complexity and how fast it’s performed, the “inverted” pyramid I’ve observed in our context is focused more on scale. Starting from the bottom, unit tests remain the foundation. They give us fast feedback loops and catch potential defects early, for example, including defect clustering or intertwined edge cases. Manual testing and E2E still happen before and after releases, but only for quick validation on critical functionality. Long-running cross-team E2E suites are now rare. I’m not entirely sure whether this will become a problem in the long run, but for now, it works for us. Instead of relying heavily on full end-to-end coverage, we’re using dogfooding (performed manually) with the combination of existing automation, which only covers the critical features. It’s lighter, more practical, and helps us maintain speed without causing brittle and flaky tests in E2E pipelines.
Where the biggest shift happened, I think, is from the integration layer and upwards. Particularly in how we execute system-under-test and contract scenarios. The QA team still performs API, database, and service-level testing and so on, but the structure of our test scenarios has changed. Previously, we mostly asserted functional correctness between request ↔ response behaviour, then verified results in the database. As we can see something like:
if response.status_code != 200:
assert_response_body()
or_another_assert_method_here()Now, typically, it’s become different:
if response.status_code != 200:
assert_response_body()
.chain_to_other_services()
.chain_to_other_services()
@parameterized.expand([A, B, C])
def test_expanded_services():
query_statement = DBClient()
query_statement.execute_sql()
for query_statement in response.body:
data = assert_raises_with().chain_to_other_services()
return dataThat assumption to validate the logic remains the same, as it is based on the requirements basis, but now it covers a much wider approach, especially when dealing with distributed data, system contracts, and an unexpected scale of driven edge cases, which is leading towards data inconsistency issues, as it happened before throughout 2022. In my cases, I’ve had to pair with my coworkers to simulate race condition testing by injecting a customised Redis LUA script and porting in the existing code to identify what parts are causing the leakage, and we run the customised load testing, which just makes me feel dumber (lagi dan lagi) since I didn’t know such kind of testing approach even exists 🥲.
The top layer is where we become our testing battleground. Honestly, most of our testing was conducted in the production environment, but of course, with strict rules to safeguard the system and in appropriate manners. I’d asked my senior QA about how frequent they’re team tests on production, at scale of 5, she’s reassuringly saying that 3 or 4 would test on production. And this also happened to me HAHAHA.
Well… I’m not saying this should be the standard for every company, nor am I encouraging reckless production testing. There are prerequisites before anyone can even think about doing it safely. The decision to test in production doesn’t come from our laziness or a lack of discipline or whatever reason that comes up with, it is actually grounded in reality. We often don’t have enough time to replicate complex scenarios, our data isn’t always synthetic enough, and staging rarely mirrors real-world conditions. The old advice that’s told to me, “Kenapa harus production kalau ada staging?” has been completely debunked in my current experience. Staging, at best, reflects 5–10% of production behaviour. The most critical, user-impacting issues almost always reveal themselves in production. At the same time, I’ve always remembered software testing principles: Exhaustive testing is not possible.
Thus, our philosophy becomes: test on prod or no bother to test at all (alias, user kami adalah target utamanya)
What kind of testing is at this level?
Feature testing still happens in development or staging, but beyond that? We deploy, observe, and learn in production. We use traffic replay, synthetic monitoring, and observability logs as primary and secondary signals for failure analysis. Sometimes we roll out a feature to only 1–5% of users and evaluate real behaviour behind the feature flag, especially when a service depends heavily on external systems. Certain teams also run disaster recovery tests and cost-optimisation stress tests (honestly, this is a new thing for me), while others experiment with shadow deployments to validate new services under real traffic before public exposure. All of these things are not limited, and we have a variety of testing strategies with the primary objectives such as:
- How resilient our systems are at scale
- What kind of SLA are for the issues that we’re going to “tolerate” and “isolate” in production
- At what level are we confident enough that even though there’s a disruption, we’re still recovering as soon as possible
- We don’t try to elimate issue, but our testing perspective becomes nrima ing pandum that most issues will immediately reach the production stage. No matter what happens, just accept it 🤣
- Test coverage doesn’t matter since all tests are eventually going to be flaky at a certain point. And thus, we must spread out our testing radius.
Typical Work for Me
To be fair, on a daily basis, researching was the most refreshing and humbling experience. It constantly makes me feel like the dumbest person in the room (and I like that). The testing landscape around me has also changed drastically this year. Sometimes I catch myself saying, “Loh, bisa ya test kayak gini?” or “Anjirr, kalo perusahaan sebesar Google/Netflix, mereka ngetestnya gimana ya?” or “Ini gak kenapa-kenapa kan ya, kalo test kayak gini?”
What’s interesting is that my work rarely revolves around “typical QA or SDET” anymore2. Instead, it’s more specialised, sometimes oddly niche, and deeply technical, for example:
- Testing binary logs for the MySQL database (I’d never thought about that before, since, why would you even do that HAHAHA)
- Testing for infrastructure consistency and linearizability, finite state-machine testing (think of it as you want to test database replication with a good number of instances)
- Testing in an isolated environment to capture interleaving bugs during race conditions, like you seriously need an isolated environment under extreme concurrent users
- Deterministic simulation testing when we were having a database migration or backup
- Testing for Redis cluster, message broker, event queue and such. But not through the API, rather, I was implementing some kind of test harness around them.
- Developing customised assertion tests to validate data integrity and consistency throughout data pipelines → external/internal services → database.
- Researching and making an early version of automation testing for LLM-generated content with the combination of HiTL (human-in-the-loop)
- Distributed performance testing. Many thanks to this Govtech article, as my main reference, where they managed to scale out the testing load beyond the limit.
- Customised Maestro framework for the mobile apps team. We adopt Maestro to write UI automation, but I extend its capabilities further.
Most of the activities I listed above aren’t recurring events, they’re atypical tasks that I usually execute per event rather than as periodic cycles. However, many of them evolve into somewhat automation-ready testing. So, whenever an issue happens again, we just enable it again so that it can be triggered at any time during regression. That way, when a similar issue resurfaces, we don’t start from zero: rather, we simply re-run the relevant scenarios or just modify the existing functionality based on needs. Manual or exploratory testing still plays a role in my workflow, but mostly for uncovering UX issues, which contributes to my performance evaluation as well. And whenever the mobile app releases a new version, I allocate time to actively explore and test features in a more freedom, user-centric way.
In terms of automation, I’m still actively involved in developing and maintaining UI automation for mobile apps, as well as improving our API automation using internal tools we built earlier. Realistically, my time allocation for automation work hasn’t always been time-consuming. On a typical five-day work week, I might only spend a day or even just half of a day dedicated to contributing to the automation testing thingy. The rest of my time is often occupied by production monitoring, reproducing production issues, escalating and distributing testing tickets, internal tooling development, and handling release responsibilities from Wednesday to Thursday. Performance testing happens biweekly or monthly. Most of the work I write is in Python, occasionally JavaScript/TypeScript, and rarely Go. We don’t have a de facto or a standard framework: instead, we prioritise using the right tool for the right context for the right job.
How about with chaos engineering??
To be honest, in my 5 years here, we’ve only initiated chaos engineering once. The outcome was… eye-opening and quite horrendous. It exposed weaknesses that pushed almost every engineering team to spend an entire year fixing and improving their services. That year, we collectively shared a KPI and OKR around system performance and reliability improvements. But it raised a question that still lingers with me personally, such as: Are we applying chaos engineering correctly? Or do we need a version that better fits our environment? Many articles that I’ve read before describe chaos engineering practices at massive-scale companies, and replicating them blindly doesn’t make sense for us. Our system scale, traffic patterns, and constraints are different, so our approach must be adapted thoughtfully, must fit and be strictly bounded by prerequisites, context, and feasibility within our tech ecosystem.
Wrap-up, but what were future that I should take…
Looking back at my early career years, I was fixing typos immediately because every bug felt equally important. Today, I’m working and developing some kind of testing framework for linearizability in distributed systems where correctness is nondeterministic, and production is the primary testing ground (which, if I’d look back then, would scare me HAHA). The tools changed from Selenium, Appium, and Google Sheets to custom test harnesses for distributed systems, and now emphasised with AI-things, which all of them surprised me the most. The philosophy changed from preventing all bugs → fix critical or unresolved issues by risk and prioritise → detect and recover quickly. So has the scale changed, from a few users towards 5000 internal users, gradually increasing to 50K, 100K, 200K active users, to more than 5M monthly active users
I think the biggest change was me. I started learned to accept, understanding the uncertainty and ambiguity, but at the same time also needed to discover with it in order to find an answer, which made me feel prone and drained throughout the years. Well, I surely can’t deny this. To make decisions with incomplete information. To measure success not by perfection, but also by resilience. To find comfort in discomfort, because I have to think that’s where growth lives. The mental load of making quality decisions apparently burden me enough with overloaded information. Every “no” or “yes” decision carries risk and greater weight on it. This also happened to the “no/go” decision, which also impacted the business value or other things that I may have missed. Every compromise between speed and quality feels like a small “snowball” when causing an upcoming roar, even when it’s the rational choice. Oftentimes, I genuinely ask myself whether I’m making the right calls or just making calls because someone has to.
Now, the main question, at least for myself: would I do it all over again?
Well, tough question, even is just a question that I made. I’m still unsure, honestly…

Footnotes
-
Decisions don’t come purely from experience or seniority. They come from being consciously aware of context, actively evaluating trade-offs, reflecting on consequences, and emphasizing our actions so it can be aligned with the objectives and outcomes ↩
-
Honestly, throughout 2025, my role often overlapped and extended far beyond what would be considered “typical”. The thing that keeps coming to mind is “Palugada” or “semua dikerjakan”. I’m not sure whether this is driven by our extremely fast-paced environment or simply our culture, probably both. What I’ve described so far is only the tip of the iceberg of what I actually do day to day. On some days, I function like a full-stack engineer. On others, I go deep into UX work, helping the design team with secondary research. There are also moments when I step in as customer support, or even take on the role of release manager. The boundaries blur constantly, but that flexibility has become part of how the team operates and part of how I’ve grown. ↩