Motivation
I didn’t set out to recreate the entire MapReduce framework like the Hadoop ecosystem. This writing came about because i received an assignment from my lecturer on the subject of distributed big data. The assignment required us to delve into and implement the MapReduce programming model.
In this particular context, MapReduce is employed to handle the splitting and chunking of large clusters of data, which are then condensed and consolidated into a unified dataset. However, i won’t be using it to perform cluster computations. Instead, my focus will be on counting the occurrences of words in a given dataset.
Programming Model
Given the aforementioned context, we can represent the MapReduce process using a simple notation (it’s non-mathematical operation), like to
f(x) = yIn this notation, f(x) signifies the data transformation process, with x representing the input data, and y representing the resulting aggregated output. Latter on, the MapReduce transformation can be broken down into three distinct stages:
- Mapper: This stage involves a function that calculates the frequency of word occurrences in the dataset after breaking down sentences into individual words.
- Shuffle and Sort: After the mapping process, the results are sorted. The data is structured as key-value pairs (the specifics of the data don’t matter at this point), and it’s sorted based on the frequency of the keys.
- Reduce: The final step involves simplifying and aggregating the key-value pairs to produce an output dataset with unified results.
Python’s Implementation
I opted to implement this using Python, and to enable parallel computing for the MapReduce process, we rely on the Threading library. The MapReduce process necessitates parallel or asynchronous execution to ensure simultaneous transformation without waiting for one task to complete before starting another. The parallelization process using the Thread library can be visualized as described below:
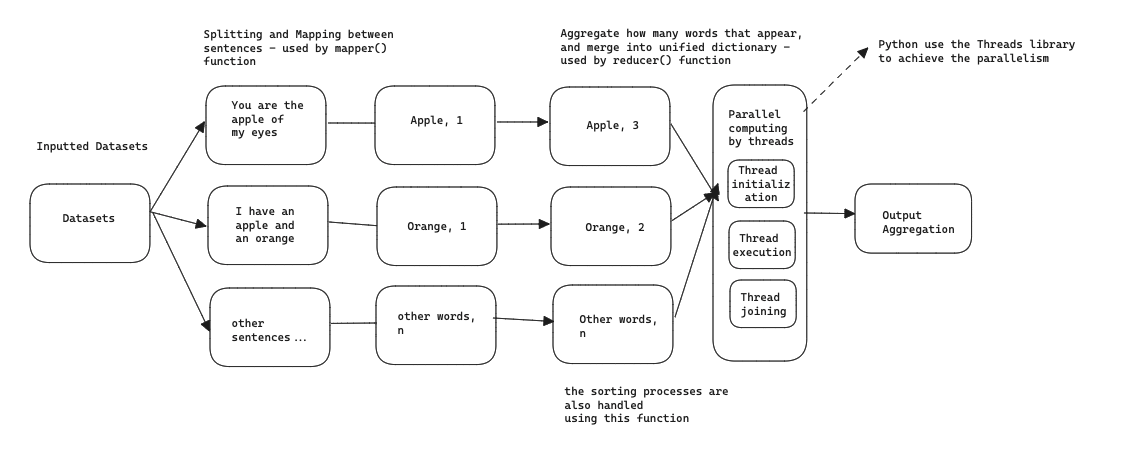
The parallelization process is accomplished by initializing a Thread instance with the start() method. This leads to parallel processing of the intermediate data that was previously shuffled and sorted based on key frequency. The entire process is concluded by joining and ending the Threads using the join() method.
The provided code for representing MapReduce resembles the following :
import threading
import csv
from collections import defaultdict
datasets = [
"You are the apple of my eyes",
"I have an apple and an orange",
"My eyes are looking for the apple",
]
def mapper(chunk, output):
# mapper function used to tokenize the words
# that given by datasets, split between
# those words and emitted into a new pair key-value
for line in chunk:
for word in line.split():
output[word] += 1
def reducer(mapped_data):
# reducer function to aggregate how many words
# that appears given by the mapped data in all of
# the dictionary (merging process)
word_counts = defaultdict(int)
for mapping in mapped_data:
for word, count in mapping.items():
word_counts[word] += count
# since the implementation is done manually,
# ensure that words value is being sorted
sorted_words_count = dict(
sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
)
return sorted_words_count
def computing(num_of_threads):
# method used to enables the parallel computing process
# by split the datasets into each chunks and each chunks
# would be processed by different threads
threads = []
chunk_size = len(datasets) // num_of_threads
output = [defaultdict(int) for _ in range(num_of_threads)]
for index in range(num_of_threads):
start = index * chunk_size
end = (index + 1) * chunk_size if index < num_of_threads - 1 else len(datasets)
chunk_of_data = datasets[start:end]
thread = threading.Thread(target=mapper, args=(chunk_of_data, output[index]))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
return outputreferences of sorted function: https://www.freecodecamp.org/news/sort-dictionary-by-value-in-python/
What particularly interests me is the partitioning of the datasets into smaller chunks. I want to ensure that there’s no overlap in the dataset splitting. Therefore, i divide the data into a prefix for the start of the data chunking process and a suffix for the end of the chunking process. This can be observed in the iterative process that continues until the thread index is exhausted (based on the number of datasets and threads used). Once the prefix and suffix processes are complete, they are designated as a chunk_of_data, which is later initialized and executed by a running thread.
We can run this program just by simply called each particular method like :
compute_result = computing(num_of_threads=2)
map_reducer = reducer(compute_result)
print(map_reducer)And the following output would like this :
{'apple': 3, 'are': 2, 'the': 2, 'eyes': 2, 'an': 2, 'You': 1, 'of': 1, 'my': 1, 'I': 1, 'have': 1, 'and': 1, 'orange': 1, 'My': 1, 'looking': 1, 'for': 1}Notes: Actually, threading in Python doesn’t run solely in parallel-terms because there are limitations related to the GIL