Initial written and research date: 19 April 2023
Accepted as one of the recipients of research grant funding from Kemendikbudristek
Accepted date: 30 May 2024
Challenges in testing
When you try to search for the keyword “testing in distributed systems”, the first thing that comes up is dozens of articles, research saying it’s hard.
This may not be an overstatement, as testing distributed nodes or components that work together poses many challenges. As per this research report were written, there is no one-size-fits-all solution for testing these systems, as each company has its own approach. For example:
- Netflix uses a Linear-driven fault injection approach [1]
- Amazon Web Services implemented a method called deterministic simulation [2]
- Cassandra has their Jepsen tools and fuzzing test [3]
- Many other companies have different methods for testing their systems.
Essentially, a one-size-fits-all solution doesn’t exist because the behavior of each company’s adopted distributed system varies. The most suitable approach is to have a comprehensive understanding of distributed systems, particularly customized to the specifics of one’s own company—if a distributed system is in place.
We particularly identifying, and found a several challenges of testing in distributed systems such as:
- The Complexity of Distributed Systems: The behavior of distributed systems can be intimidating for some reason. Seemingly straightforward networking events like requesting and responding can performed unexpected or unpredictable behavior from development to production due to the non-deterministic nature of distributed systems. For instance, a few nodes may performed varied behaviors — one service might send requests while another might receive them, leading to complicated process in achieving consistent outputs from interconnected services. This challenge is further amplified during the replication process between components, potentially resulting in divergent bugs.
- Managing Failures and Mean Time to Repair: Identifying all potential edge cases related to distributed systems through testing is a demanding task. Bugs might not be immediately visible, if it wasn’t triggered through specific events such as emerging during partial failures caused by external services or specific failed requests. This complexity intensifies in real-time distributed systems. In addition to debugging and rectifying an issues, the speed at which engineers address these problems, restoring system functionality, becomes crucial. This necessitates not only addressing known edge cases but also accommodating unforeseen scenarios and aligning with product requirements.
- Propagation of Issues Like an Epidemic: Bugs or errors in distributed systems have the potential to spread widely, much like an “epidemic”. A failure in one component can trigger a chain reaction that halts the entire system until the underlying cause is resolved. Once addressed, there remains a risk of recurring bugs remaining undetected until they resurface. Moreover, individual node errors or bugs can emerge without any direct request-response interaction, adding an additional layer of complexity.
It’s evident that testing in the context of distributed systems is quite complex and context-dependent. Understanding the peculiarity of one’s system and acknowledging the perplexity of distributed systems is fundamental to developing effective testing strategies.
At the time this research was written, we can share several strategies for testing distributed systems, drawing from the insights gained within our present organization. While these approaches might not necessarily align with universally accepted best practices or recommended standards, the information presented here combines the results of empirical study with scholarly investigation. This combination attempts to address and offer possible further investigation for the issues we want to talk about in the next parts.
State of testing as the obstacle
Our current company, Maukerja Malaysia, is a job portal platform that serves customers and users in the Malaysia region. Within our platform, we currently have around 50 interlinked services, some internal and others operating independently without relying on external resources. This figure is projected to increase to approximately 70 services when incorporating additional API services and external functionalities like ElasticSearch for search engine communication, Redis for information metadata retrieval, as well as core technologies like Kafka, and Firebase for Push Notifications, among others.
All these components collectively share a common challenge: the context-dependent difficulties.
With numerous services and diverse technologies at play, various common issues arise during the testing of these distributed systems. We’d like to focus on two main challenges, differentiating them based on both engineering and human perspectives.
Although overcoming these obstacles is still possible, further difficulties arise when taking into account the human factor, such as:
- Time constraints for testing: Our available testing time is relatively limited, possibly distinguishing us from other enterprises. Given that our foremost priorities are our business operations and user experience, a tool or framework that aids us effectively within this restricted timeframe is essential.
- Uncertainties in testing outcomes: Understanding about potentially inaccurate test outcomes instill a sense of unease. Despite having contingency plans and rollback strategies in place, the lack of prior large-scale testing experience induces a higher learning curve. This challenge is compounded by our resistance to the unknown factors.
From an engineering vantage point, there are additional disadvantages:
- Engineering complexity: This challenge aligns with the aforementioned time constraints. Implementing solutions correctly, choosing appropriate testing methodologies, and accounting for factors like fault tolerance, consistent data testing across shared distributed resources, and handling partial failures become relevant concerns.
- Fluctuating test reliability: The transition from singular unit or integration tests, where false positives are rare, to comprehensive end-to-end tests poses difficulties. Failures in any one scenario can lead to a cascade of failures across all tests, causing interruptions and false results.
- Complexity as a non-trivial task: The impact of a service outage resonate through interconnected systems, halting functionality across the board. The rapid loss of revenue, user traffic, and an increase in user complaints highlights how difficult it is to resolve such problems in a matter of minutes. Looking at this issue from several perspectives shows how complex it is.
Though we still maintain that the testing pyramid is a de facto solution for scenarios like these, it’s an approach that’s suitable to our current organization. We were sticking to the best practices in testing software systems: performing and initiating with unit tests for core components, advancing to integration tests encompassing internal and external services, and ended in end-to-end tests scrutinizing functionality. This incremental approach involves constructing these test components independently, each addressing specific scenarios.
However, despite our sticking to these practices, there remain shortcomings. Our concerns revolve around extended testing durations and the occasional persistence of bugs and interleaving bugs even when deploying well-structured testing methodologies.
Evaluation of the testing hierarchy
Likewise, there is a necessity for a solution that is universally applicable, catering to our system’s specific requirements. The testing pyramid, while comprehensive in many respects, sometimes seems redundant in scenarios like those encountered in our workplace. At MauKerja Malaysia, our system’s behavior is complicated linked to its multitude of components, introducing a need for focused attention on factors such as data consistency, reliability, and network communication across interconnected elements.
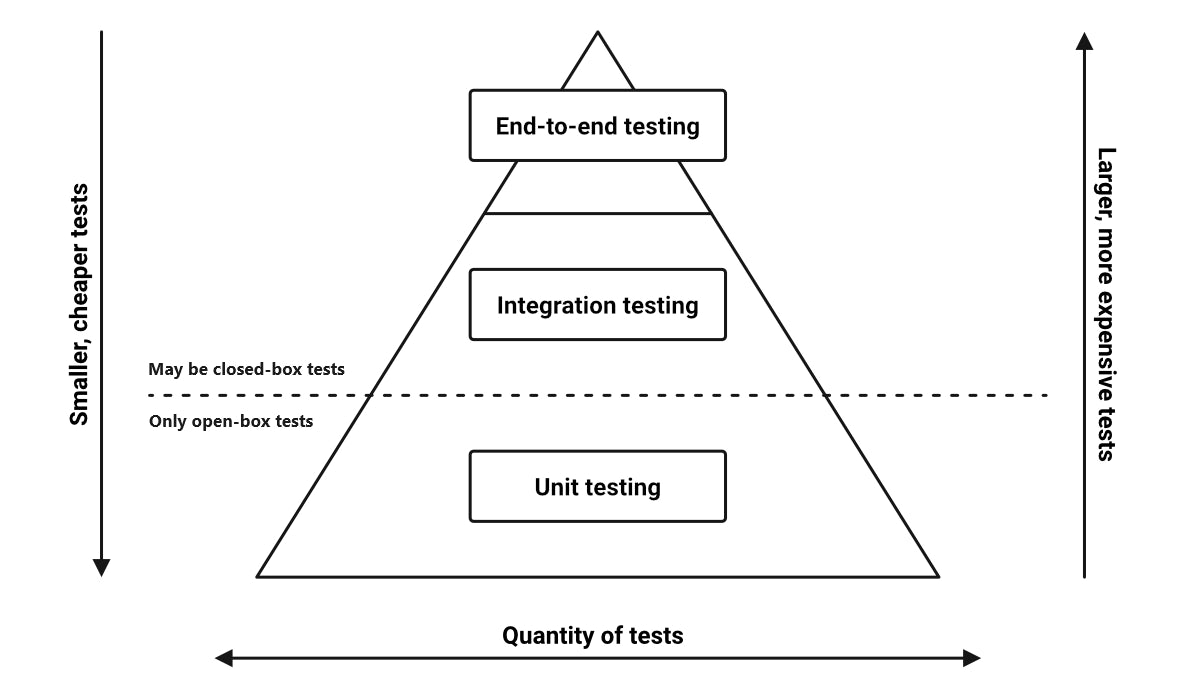
This might be a debatable for some reason, but the testing process in our context could potentially be optimized. When our QA team undertakes functional tests — be it manual or automated —consider the instance of testing search engine functionality via client-based interactions. This process would trigger certain API endpoints that connect to other services. This leads to a reevaluation of the role of unit testing (not to suggest complete removal of unit test) and the potential for a direct integration testing approach. However, a key caveat applies: meticulous attention must be devoted to ensuring the integration testing covers both the System Under Test (SUT) and incorporates stubbing for external services like libraries and dependencies.
Consequently, a more comprehensive perspective becomes imperative, cut above the rest of conceptual paradigms like the test pyramid [4]. Moreover, it’s noteworthy that the services underpinning business operations at Maukerja Malaysia extend beyond organizational boundaries — cross-organizational section, implying several data processes are reliant on inputs from other teams or external services. This aspect requires careful consideration to ensure the system’s robustness and coherence.
Maritest
Approximately a year ago, we arrived at the realization that our distributed system’s testing procedures at the organization demanded a testing framework or tools capable of streamlining the process from two distinct angles: comprehensive coverage of vital APIs and user-friendly adoption by our development and QA teams. In shed of this, we took the initiative to develop an internal tools library, known as Maritest (formerly), with the primary objective of simplifying the creation of integration tests for APIs.
Maritest was designed to minimize the complexities associated with writing integration tests by abstracting the assertion and validation procedures. Traditionally, these processes are typically implemented during top-down approach testing. With Maritest, we’ve separated the input-output validation checks from the unit tests and encapsulated them as distinct methods, accessible under the Maritest framework. Consequently, this approach detaches the testing process from the unit tests themselves, allowing for greater clarity and modularity in our testing practices*.
This library has proven to perform as anticipated, effectively identifying potential errors and mapping the occurrence of critical failures. Its success reinforces existing research indicating that such straightforward testing practices can act as a safeguard, mitigating the likelihood of subsequent failures that might arise from inadequately managed errors in the code [5]. To be more precise, The purposes of we’d developed Maritest itself also act as a “progenitor-of-checker” when the developer does not cover all of the aspects during the unit test process.
Furthermore, considering the developer experience, this library has substantially quicken the integration test creation process. This assessment is grounded in the measurable increase in the number of test cases authored per sprint. Before the incorporation of Maritest, our QA team necessitated an entire sprint (equivalent to a two-week period) to draft approximately 10 test cases. With Maritest’s integration, the time required for this writing task has been reduced to a two-day effort—as you can see on the figure table below, resulting in a successful reduction of the workload by up to eight days, and enabling the creation up-to 20 test scenarios each week.
| Method | Test Case Creation | Duration |
|---|---|---|
| Without Maritest | 10 test cases/sprint | 5 test cases/week |
| With Maritest | 40 test cases/sprint | 20 test cases/week |
In addition, the library also addresses a critical scenario that should be covered in distributed systems: performance testing, which relies on varied environment variables within the development or staging environments.
However, it’s important to acknowledge that the library is not without its limitations. From a functional standpoint, Maritest is not precisely addressing the problem for testing interactions between distinct components within the system.
Improved solution: Empowering Method Chaining
While Maritest itself is going well, but still, for heavily intense testing such as data processing or tests for services that are connected to other services it is still not capable enough and could not cover that.
Given this context, there exist various potential alternatives, and one of these alternatives involves employing the chaining method. This programming pattern involve the sequential invocation of multiple objects, enabling the procedural and simultaneous execution of these objects based on the devised test scenarios. In the context of distributed systems, this approach could be a viable solution if we aim to conduct a systematic testing process to find a potential error for each scenario [10], particularly when evaluating the interactions between different components, much like when scrutinizing the performance of one component against another.
As not to confuse you as a reader, in here’s example the code that is written is using Java (our primary language to write the core APIs services). while the Maritest itself is exposed as Python, so this code is used when the simulation process has been carried out.
// Copyright MauKerja Malaysia, May 2023
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import static org.junit.Assert.*;
public class DistributedUserServiceTest {
private DistributedUserService distributedUserService;
@Before
public void setUp() {
// Initialize the DistributedUserService and set up the database connection
distributedUserService = new DistributedUserService("jdbc:h2:mem:test;MODE=MySQL", "username", "password");
distributedUserService.createTable(); // Create the User table if not exists
}
@After
public void tearDown() {
// Close the database connection and clean up
distributedUserService.closeConnection();
}
@Test
public void testInsertAndRetrieveUser() {
// Test inserting a user into the distributed service and then retrieving the same user
User user = new User(1, "bernieng", "maukerja123");
distributedUserService.insertUser(user)
.replicateUserDataToOtherNodes()
.performAssertionsOnNode(1, user)
.performAssertionsOnNode(2, user)
.getUserByIdFromOtherNodes(1);
}
@Test
public void testLoadBalancingAndNetworkCommunication() {
// Test load balancing and network communication in the distributed service
User user1 = new User(2, "ryanfeb", "maukerjaaja2020");
User user2 = new User(3, "ginting", "12345678");
distributedUserService.insertUser(user1)
.replicateUserDataToOtherNodes()
.performAssertionsOnNode(1, user1)
.performAssertionsOnNode(2, user1)
.insertUser(user2)
.replicateUserDataToOtherNodes()
.performAssertionsOnNode(1, user2)
.performAssertionsOnNode(2, user2)
.getUserByIdFromOtherNodes(1)
.getUserByIdFromOtherNodes(2);
}
}
If we take a look, this procedure is quite straightforward, focusing on the synchronization of data across replica databases. The primary objective is to verify if the objects inserted into the system are appropriately linked and persisted within another database replica, ensuring their consistent retrieval while retaining their initial values. This validation is facilitated through the performAssertionsOnNode method, designed to inspect whether the data exists within the specified nodeId. Analogous to Maritest’s philosophy, this method functions as a wrapper that streamlines input-output validation processes.
This approach establishes a foundational framework for testing between two distinct and interconnected components. It also encompasses a simulation mechanism for assessing partial failure scenarios. Such failure can be triggered if the subsequent method invocation encounters an error. In this case, it serves as an indicator that an error exists within that specific method, halting the testing process midway through the predefined scenario. Naturally, the relevance and success of this approach are closely tied to the specific test scenario under consideration.
But, that doesn’t mean that with this solution there are no problems, there are some drawbacks after carrying out a simulation with several test iterations:
- The non-deterministic factor causes the integration testing process with the chaining method to be more flaky than ever and also difficult to reproduce. This increase in flakiness can be attributed to various factors, primarily come from unforeseen failures such as those influence by concurrent users, shifts in network behavior, and issues with external services. The source of flakiness lies in the variation of the testing paradigm. Previously, individual test scenarios were constructed in isolation. Now, all test scenarios are executed sequentially. Consequently, if an error arises, the sequence halts, and the initiation of a successful scenario is also counted as a failure due to the interruption in the midst of testing.
- Lack of self-isolation. The shift perspective from independent testing of external and other services to a sequential testing approach has implications for system recovery. In cases of flakiness, the system might not recover as promptly as before. Previously, external services or other components were tested in isolation, ensuring that issues in one area didn’t significantly affect others. With the new approach, sequential testing necessitates fixing and debugging any encountered errors to allow the testing sequence to proceed to completion. This situation poses a challenge in testing distributed systems: assessing the system’s resilience and recovery speed in the face of disruptions. The chaining method’s implementation may unintentionally make this problem worse, which could impair the system’s response time and recovery effectiveness.
Despite having trouble with the flakiness issues while using this solution, we still go along with this since this is “our best alternative” to pick up, to test several components or nodes sequentially.
Moving Forward with Observability
In complex distributed systems, observability is meant to provide insight into the “why” rather than just the “how and when”.
By employing the chaining method solution, we are not exempt from additional tasks. After conducting thorough research, we have found that the most efficient approach for identifying potentially unreliable tests is to enhance the visibility of integration tests. This can be accomplished through various means, including replaying snapshots in the event of errors within specific services (typically achievable in end-to-end testing only), tracing the entire test scenario, and generating logs that provide insights into different components or node IDs. Robust open-source tools like Jaeger are available for this purpose, or a manual implementation can be developed if time permits.
While implementing this may not be trivial and requires engineering effort, it is a crucial part of the process. With tracing between components, we can identify bottlenecks and points of failure, track resource usage (such as CPU and memory), monitor error rates, and gather other important information that can inform future prevention efforts.
It’s also important to note that even when we reach the ready-to-deploy state and all features have been deployed, observability remains a crucial part of the process. For example, we may need to conduct static root analysis or examine trace logs for failures, crashes, slow performance, and other important metrics that help identify damaged components or sources of slow performance.
Bugs: beyond production and to the infinite
Experiencing these complexities, it’s become evident that establishing proper post-production and pre-production tests remains an important goal. The aim is to minimize the likelihood of “bypass” or “interleaving” bugs that often manage to infiltrate and manifest in the live production application.
However, this undertaking has been significantly more difficult than planned.
The reality is that there’s no definitive solution or clear-cut answer to executing flawless testing, as each approach or method carries its own set of compromises. The testing landscape presents a series of choices, each involving its share of benefits and substantial trade-offs.
It’s acknowledged that we might possess a certain degree of cynicism regarding the inevitability of bugs surfacing in production applications. Nonetheless, we can derive some insight from this acknowledgment. Bugs that arise in such contexts tend to stem from unanticipated scenarios that haven’t been adequately addressed in the testing process.
Moreover, as highlighted earlier, the goal is to achieve a compromise between effective integration and end-to-end (E2E) tests that run quickly and don’t suffer from hours-long delays. This emphasizes how crucial functional automation testing is as a quick way to speed up testing processes.
With these considerations in mind, several approaches that are generally employed during our experimental endeavors. These approaches part of whole ongoing efforts to navigate the intricate landscape of testing in distributed systems, with the overarching goal of bolstering the robustness and reliability of our applications
- sanity testing. perform functional tests quickly to see if the feature is running as it should be
- regression testing. we can selectively integrate or cherry-pick specific regression tests depending on the cases or scenarios at hand. It’s possible to opt for comprehensive re-testing of all core features, or alternatively, focus solely on the highest-priority ones. Depending on these factors, regression testing may lead to the discovery of new bugs, particularly those associated with recently introduced features*.
- exploratory testing. This approach entails ad-hoc testing, wherein testers delve into the system to uncover potential issues and assess the system’s behavior in various scenarios. In this phase, we essentially provide access to end-users or stakeholders, allowing them to conduct tests autonomously. While this approach may carry certain risks, it remains a vital step for validation and verification purposes.
Caveats
Despite our efforts in implementing various testing approaches, certain critical areas remain to be adequately addressed, such as fault tolerance and post-deployment reliability. Currently, our execution of tests like performance or load testing is not as frequent as it could be, usually motivate by directives from higher management or impending campaigns and events.
We have conducted performance tests utilizing Maritest and also JMeter in development and staging environments, providing valuable insights into system behavior. However, we’ve been reticent to extend these tests directly to the production environment. This hesitation stems from concerns about possible new problems that could appear, even while testing according to recognized procedures. These ambiguities revolve around worries such as:
- what if we poke another bug that is obvious in production?
- what if we made another bug although we already applied a proper testing method?
- or, maybe we actually don’t know what’s the recognize and how to test it?
all of these questions can actually be answered absolutely exhaustive testing is not only impossible but actually it would be very unlikely to happen if there are many series that we are going to test (in this case, it is our test component or service) [6].
Furthermore, the task of testing alongside external service dependencies or executing comprehensive end-to-end (E2E) tests within the production environment presents a greater challenge than initially anticipated. This complexity is primarily rooted in the critical need to ensure the accurate configuration of all pre-established services.
A dilemma arises when considering the utilization of techniques like mocking or stubbing to streamline the testing process. While these strategies effectively disengage tests from actual services, minimizing external dependencies, they introduce the potential for divergence between the mocked data and the authentic production data. This discrepancy in data can result in differing behaviors, potentially giving rise to unforeseen complications when the application interacts with genuine production data.
The challenge lies in synchronizing between the demand for isolated testing and the necessity for accurately simulating production-like scenarios. This requires needs judgment regarding the appropriate instances for implementing mock data and stubs versus the situations that warrant direct interaction with genuine services, even within the production context. Achieving this balance is crucial to conducting exhaustive testing while mitigating the possibility of overlooking intricacies that might lead to post-production issues**.
Apart from that, we also need to think about connecting all of those services together without any hassle and the clean up after doing the test.
In all fairness, we’ve contemplated several approaches to address this challenge. One viable solution involves leveraging Testcontainers to facilitate test bootstrapping, effectively emulating real services. However, it’s important to acknowledge that this approach also introduces its own set of considerations, particularly related to the level of engineering effort required.
Closing Thoughts
Overall, testing distributed systems is a complex and challenging process that requires careful planning and consideration. While there is no one-size-fits-all solution, and as this research was written doesn’t fully answer some of the outlines that we previously presented, one thing that we can say for sure is: that a combination of different testing strategies and tools can help ensure the system is reliable and performs as expected. It’s also important to implement observability capabilities to gain insight into the system’s behavior and identify potential issues before they become critical problems in production.
Notes
-
To reiterate, this type of experimentation seeks to exclude non-essential parts during the unit testing process. Therefore, unit testing only covers the most important aspects at the end of the process. You can use the Pareto principle, where 20% of testing is dedicated to unit tests and the rest is for integration and functional testing. Though this may be debatable, the main goals are:
- achieving delivery time while maintaining the integrity of unit tests
- isolation to avoid unnecessary code errors, including input-output validation processes that often occur at lower levels.
-
This situation resembles a doubtful advantage. If we choose not to employ synthetic data for production testing, we may encounter various issues, such as data inconsistency when sharing data across different nodes. This discovery is supported by a previous paper that revealed 85 out of 103 bugs found in large-scale distributed systems resulted from state inconsistency among nodes [7]. Conversely, using original data in production also raises concerns about security, real user privacy, and potential overlap with existing data. We think the best bet that we can do it’s combining between them depending on the specific context or requirements.
-
Previously, our practice didn’t include conducting regression testing prior to the production release. However, as a result of our prior experiences, we encountered numerous issues that arose post-production release, stemming from various sources such as customer support, project management, user feedback, and other factors. Consequently, our team collectively decided to introduce regression testing as a preliminary step before the final deployment to the production environment. Typically, these regression tests are completed within a single day, though they may extend to two days in cases where issues prove challenging to replicate.
Fault-tolerance and resiliency tests
Although these articles don’t explicitly stated the direct testing or validation of our distinct services’ individual performance, we managed to conduct a series of experiments targeting certain components that interconnect across different services to achieve a unified objective. In this pursuit, we’ve harnessed the Python asyncio library to orchestrate event-loop-based requests. This approach primarily seeks to assess two key aspects: the resilience and speed of our system’s recovery following a downtime incident, and the overall efficacy of our system’s functionality. Presented below is a snippet exemplifying how the code is structured :
async def test_fault_tolerance(self, num_of_requests: int, duration: float):
for endpoint in self.http_endpoints:
resp = await self.get(endpoint)
assert resp.status_code == 200
await simulate_node_failure(self.http_endpoints[0])
response_counts = {endpoint: 0 for endpoint in self.http_endpoints}
if num_of_requests is None:
num_of_requests = 100
async def make_request(endpoint):
for _ in range(num_of_requests):
resp = await self.get(endpoint)
logging.info("Make an HTTP request in the certain endpoints")
if resp.status_code == 200:
response_counts[resp.url] += 1
await asyncio.gather(*[make_request(endpoint) for endpoint in self.http_endpoints])
assert (
response_counts[self.http_endpoints[0]] == 0,
f"This {self.http_endpoints[0]} received any requests after failure",
)
for endpoint, count in response_counts.items():
if endpoint != self.http_endpoints[0]:
assert (
count > 0
), f"Certain {endpoint} didn't recover after failure requests"
# This is a helper function to simulate the delay
# before making another attempt to requests
# other services whenever one of our services is down
await delayed_node(duration=duration)
resp_after_recovery = {endpoint: 0 for endpoint in self.http_endpoints}
async def make_request_after_recover(endpoint: str):
for _ in range(num_of_requests):
resp = await self.get(endpoint)
logging.info("Make an HTTP request in the certain endpoints")
if resp.status_code == 200:
resp_after_recovery[resp.url] += 1
await asyncio.gather(
*[make_request_after_recover(endpoint) for endpoint in self.http_endpoints]
)
for endpoint, count in resp_after_recovery.items():
assert count > 0, f"Certain {endpoint} didn't recover after failure requests"
logging.info(
f"Successful make an HTTP request with success count: {response_counts}, and success after recover: {resp_after_recovery}"
)
In fact, this code proves highly adept at pinpointing the exact moment when any component or service we attempt to access encounters an issue. This capability allows us to assess the system effectively, and what truly astonished us is our newfound ability to find a pattern of failures triggered by one service’s downtime, especially when we have a clear understanding of the procedural sequence of service access.
During the implementation phase of this approach, we observed that certain services, which were tested solely for their fault tolerance, encountered multiple failures. These failures were not visible when we exclusively tested based on the positive path, especially to the search engine section which is very tightly managed with other services. As shown in the table figure below :
| Services Name | High Cohesion | Numbers of Failed Test Cases (Positive scenario) | Numbers of Failed Test Cases (Simulation of failures) |
|---|---|---|---|
| Maukerja APIs | HIGH | 3 | 9 |
| Search Engine | VERY HIGH | 5 | 23 |
| Recommendation Engine | HIGH | 0 | 3 |
| Messaging Services | MODERATE | 0 | 2 |
| Employeer APIs | HIGH | 2 | 6 |
An Experimental Approach: Mixing-up between Data-Driven Testing and Equivalence Partitioning
As you may be aware, our system comprises a complex network of 50 to 70 interconnected services, each hosting numerous API endpoints, each with its unique functionality. In practical terms, after completing the deployment process, conducting comprehensive API testing can be impractical, particularly when dealing with non-critical read-only APIs. This challenge has made it intricate for us to delineate which APIs require testing and how to execute those tests effectively.
To address this issue, we’ve proposed a method that leverages equivalence partitioning and data-driven testing. In a nutshell, the process involves:

- Segregating the APIs to be tested using equivalence partitioning. We categorize them into three groups:
- “Upper Data APIs” — which are the most critical, heavily intertwined with other services, and capable of producing significant database write operations.
- “Moderate APIs” — which hold importance but remain flexible.
- “Lower Data APIs” — which are less critical and often have minimal impact even if tested.
- Employing the results of this categorization to conduct data-driven testing based on predefined expected outcomes.
- In cases where the outcomes of API testing don’t align with predefined data or established criteria, we initiate a corrective process. This involves generating a new set of results, followed by an extraction, transformation, and loading (ETL) procedure for subsequent analysis. This iterative data-driven approach aims to obtain the “appropriate” results, which are then incorporated into the analysis phase rather than having an intrusive result [9].
- However, if the test results meet the expected criteria, a standard report is generated.
This process necessitates a robust and technical implementation. This includes the development of an HTTP wrapper for making requests to the designated endpoints, scripting for database connectivity, and custom validation mechanisms to compare input data with the database-generated output.
The testing process unfolds sequentially, implying that we don’t halt at a single stage; we continue with the verification and validation of the data output.
As a result, our primary emphasis is on optimizing time efficiency rather than quantifying the impact of this approach. In the past, manual testing combined with the need to verify data by inspecting database records used to consume an estimated 2-5 minutes per test (just for a single API). However, with the implementation of this streamlined process, the time required has seen a significant reduction of up to 95%, typically taking only 3-15 seconds (tested on multiple APIs — 73 endpoints). It’s worth noting that the actual time saved may vary depending on factors such as the number of APIs tested, their complexity, and the data under examination.
Acknowledgments
As for us, we would like to express gratitude to the entire engineering team at Maukerja Malaysia for their valuable contributions, insights, and collaboration in navigating the challenges of testing distributed systems.
Special thanks to the individuals who contributed to the process of writing this article. Their efforts included reviewing, simulating, and verifying the content.
Disclaimer
The information and views expressed in this writing are solely those of the author and don’t necessarily reflect the official policies or positions of Maukerja Malaysia, its parent company, or any other organizations mentioned. The author’s experiences and examples provided in this writing are based on specific scenarios and contexts and may not be applicable to all distributed systems environments.
References
[1] — Hunt, N., Bergan, T., Ceze, L., & Gribble, S. D. (retrieved 2023). DDOS: Taming Nondeterminism in Distributed Systems.
[2] — Alvaro, P., Rosen, J., & Hellerstein, J. M. (2015). Lineage-driven Fault Injection. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 331–346. https://doi.org/10.1145/2723372.2723711
[3] — Leesatapornwongsa, T., Lukman, J. F., Lu, S., & Gunawi, H. S. (2016). TaxDC: A Taxonomy of Non-Deterministic Concurrency Bugs in Datacenter Distributed Systems. Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems, 517–530. https://doi.org/10.1145/2872362.2872374
[4] — https://jepsen.io/analyses
[5] — Radziwill, N., & Freeman, G. (2020). Reframing the Test Pyramid for Digitally Transformed Organizations (arXiv:2011.00655). arXiv. http://arxiv.org/abs/2011.00655
[6] — Yuan, D., Luo, Y., Zhuang, X., Rodrigues, G. R., Zhao, X., Zhang, Y., Jain, P. U., & Stumm, M. (2014). Simple Testing Can Prevent Most Critical Failures.
[7] — https://www.sciencedirect.com/topics/computer-science/exhaustive-testing
[8] — Gao, Y., Dou, W., Qin, F., Gao, C., Wang, D., Wei, J., Huang, R., Zhou, L., & Wu, Y. (2018). An empirical study on crash recovery bugs in large-scale distributed systems. Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 539–550. https://doi.org/10.1145/3236024.3236030
[9] — Subramonian, R., Gopalakrishna, K., Surlaker, K., Schulman, B., Gandhi, M., Topiwala, S., Zhang, D., & Zhang, Z. (2013). In data veritas: Data driven testing for distributed systems. Proceedings of the Sixth International Workshop on Testing Database Systems, 1–6. https://doi.org/10.1145/2479440.2479448
[10] — Yuan, X., & Yang, J. (2020). Effective Concurrency Testing for Distributed Systems. Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, 1141–1156. https://doi.org/10.1145/3373376.3378484